
第5回 Elasticsearch 入門 Elasticsearch の使いどころ
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
第5回 Elasticsearch 入門 Elasticsearch の使いどころ
今回は少し、思考を変えてシステムを開発する際にどんなところで Elasticsearch を使えるのか?という視点で説明したいと思います。
最近のシステムの特徴
最近のシステムは、ビッグデータの重要性の認知、ソーシャルデータの活用など、1つのシステムでも様々な種類のデータを管理し活用するようになってきました。また、クラウドサービスやオープンソースが当たり前に使われるようになり、データを管理し活用するためのシステムやサービスも様々な選択肢があります。
そのため、最近のシステムではデータの利用目的によってデータストアを使い分けることが多くあります。
例えば、商品情報など構造化されたデータは、ビジネス要件を満たすためにデータを矛盾なく永続化する必要があるため、MySQL などのリレーショナル・データベースに保存されます。
また、更新や参照トラフィックが多くデータ数も多いゲームやモバイルアプリケーションなどで使用するユーザ情報は DynamoDB などのキー・バリュ型のデータベースを選択することもあるでしょう。
さらに、ユーザの行動履歴などのトラッキングログは S3 などのストレージサービスに保存され、大規模データの蓄積・分析のために Redshift などのデータウェアハウスや 分散処理が得意な Hadoop を使用するなどの選択肢があります。
データベースの種類によって得意不得意がある
この状況は、大規模データの蓄積・活用において、すべてのユースケースに柔軟に対応出来るデータストアが存在せず、それぞれのデータストアはある目的に特化して進化しているためです。
例えば、MySQL などのリレーショナル・データベースは、構造化されたデータをビジネス要件に矛盾なく永続化することに特化したデータベースです。SQL と言う高度なクエリ言語、検索トラフィックに対するシステムの拡張は得意ですが、データ量の増加や書き込み速度の拡張は苦手です。
Redshift などのデータウェアハウス系のデータベースは、大規模なデータの蓄積・分析は得意ですが、不特定多数のクライアントから同時に利用され、検索リクエストが大規模なユースケースには不向きです。
DynamoDB などの NoSQL は、幅広い種類の膨大な量のデータを高速かつ動的に整理し分析することを可能にする、非リレーショナルな広域分散データベースシステムです。その反面複雑なクエリやソートなどが苦手です。
イベント駆動型のシステム構成
このような状況の中、特に大規模なシステムのデータを利用する側のアプリケーションやシステムは、アクセスする情報によって異なるプロトコルや異なるクエリ言語を使用してアクセスする必要があります。
当然開発者の学習コストも高くなってしまうため、新たなユースケースが発生した際にデータを活用するのが難しくなってしまいます。
Elasticsearch の使いどころ
昨今のシステムにおいて、データ利活用におけるシステム要件を以下にあげてみました。
- あらゆる規模に拡張可能
- 検索トラフィック・データ量/書き込み速度の両方
- 様々な種類のデータを横断して検索・分析できる
- 様々な種類のスキーマに対応可能
- 様々な種類のデータ型に対応可能
- 柔軟なデータモデル
- 高速なクエリ実行とリアルタイム分析
- 高度なクエリ言語
検索エンジンというと、いわゆる検索ボックスで任意のキーワードを入力して全文検索で使うイメージがほとんどですが、 Elasticsearch はデータ利活用における上記の要件をすべてカバーすることが可能なため、参照系(検索・集計分析)のほとんどで利用可能です。
- e コマースサイトで商品情報の表示・検索やレコメンデーションで利用する。
- e コマースサイトの受注情報を蓄積して、可視化・分析、レコメンデーションで利用する。
- ブログサイトの記事を蓄積してサイト内検索で利用する。
- ユーザからのお問い合わせ情報を蓄積して検索や分析で利用する。
- ユーザの行動履歴を蓄積して可視化分析、ユーザクラスタリング、パーソナライゼーションで利用する。
- ユーザの口コミ情報を対象に、可視化分析、不適切投稿検知の仕組みとして利用する。
- テキストを含むデータを対象にして、機械学習用のデータ作成で利用する。
- システムのログを蓄積して、可視化分析、アラート検知に使用する。
- などなど
強いて向かないデータをあげると、Memcached などで管理されている利用目的が限定されたキャッシュデータは Elasticsearch にインデックスしてもあまり意味がありません。
データ駆動型のシステムを Elasticsearch ベースに考える
データ利活用におけるデータ駆動型のシステムを Elasticsearch をベースに考えてみましょう。 私の考える Elasticsearch ベースのデータ駆動型システムは以下のような構成です。
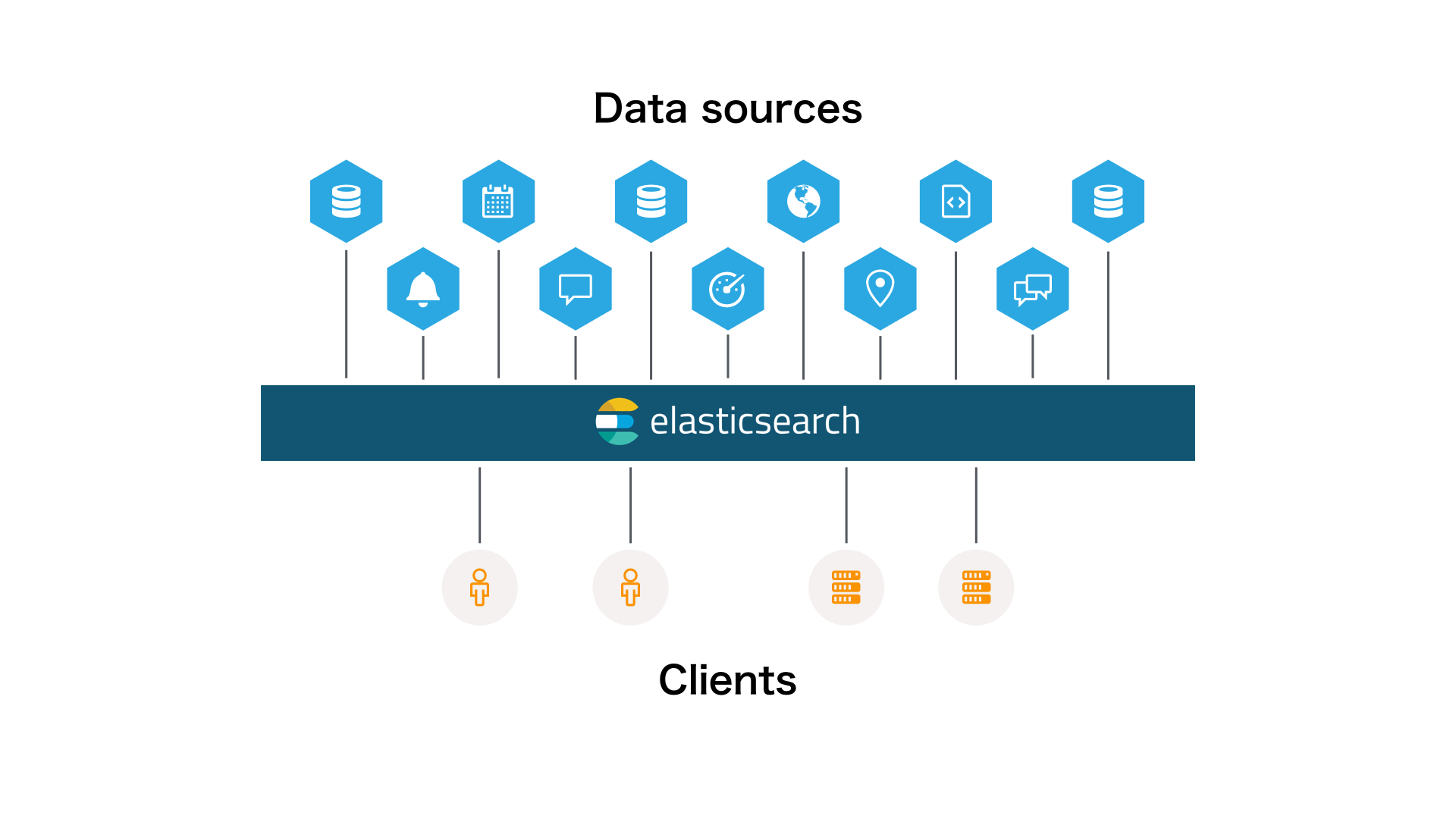
すべてのデータを Elasticsearch にインデックスすることで、データの検索や集計など参照系のインターフェースを統一することができます。 また、必要に応じて複数のデータソースを横断して検索や集計・分析することが可能になるのです。 それと、リアルタイム分析が優れているので、バッチ処理の開発が格段に少なくなります。
ここで重要なのは、Elasticsearch は他のデータベースを置き換えるものではないということ。 特にオリジナルデータを管理しているデータベースの置き換えは、基本的には避けるべきです。この理由は、辞書やインデックス処理の変更が必要な場合はオリジナルのデータをもとにデータをインデックスし直すこともあるからです。また、リレーショナル・データベースと比較して、データの設計が非正規化されるためデータの内容が冗長的になります。 もし、オリジナルデータを他で管理していて、検索や分析のためだけに使用しているデータベースは置き換えを検討することができます。
それでは、このシステムの特徴を見ていきましょう。
あらゆる規模に拡張可能
Elasticsearch の Index は複数の Shards (Primary/Replica) で管理されていて、その Shards は Node (Server) に配置される仕組みです。そのため、検索トラフィック増大やデータの増大(書き込み速度の低下)の両方に対して、Node (Server) を増やすことでシステムを拡張することができます。
以下の図は1台以上の Node で構成される基本的な Cluster 構成です。
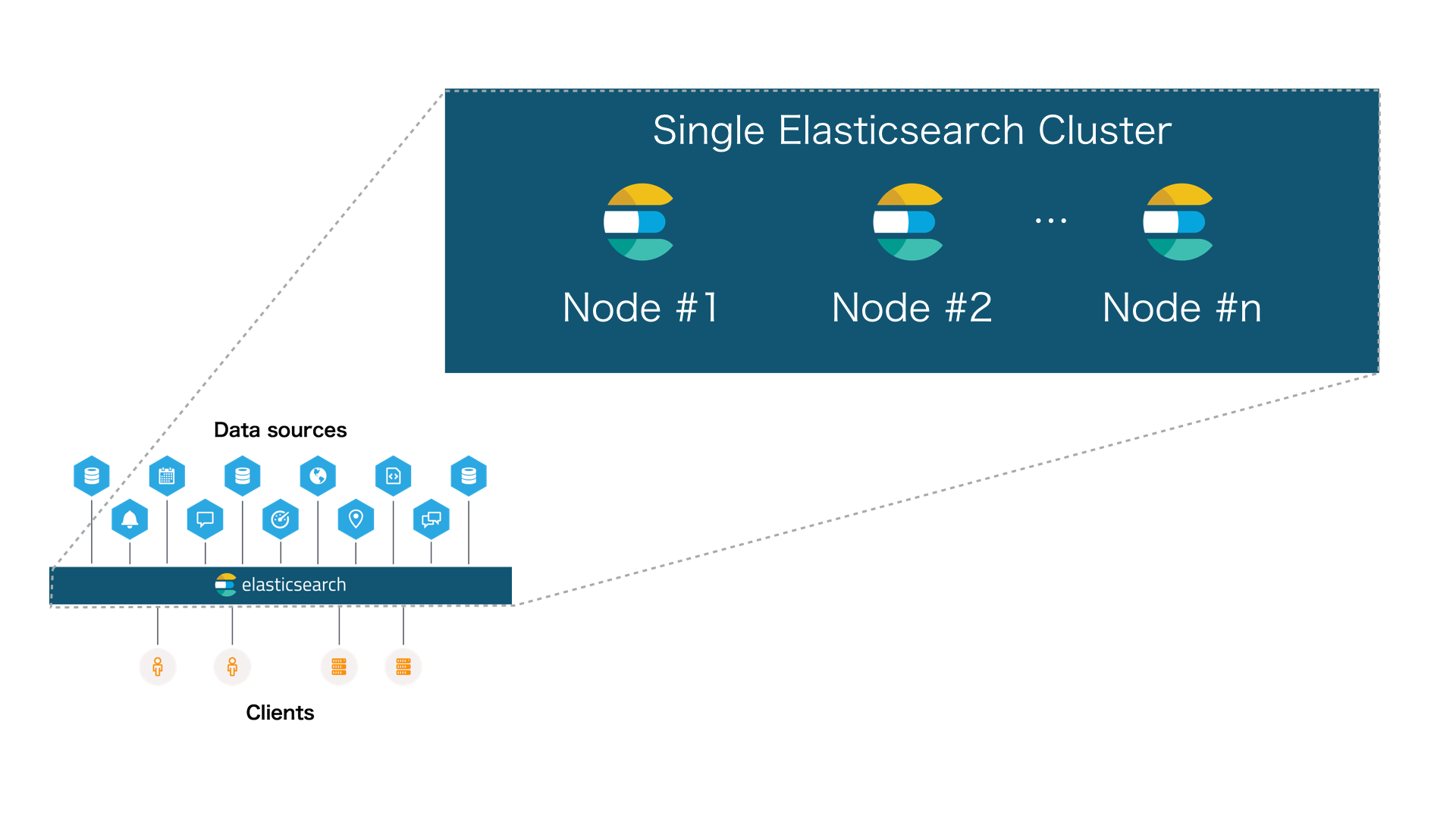
Single Cluster の基本的な構成でもかなり大規模なシステムを構築可能です。
超大規模なシステムも構成できる
さらに、複数の Cluster を統合してさらに大規模なシステムも構成可能です。
以下の図は、複数の Cluster から構成される超大規模な構成です。 インデックスなどの書き込みはそれぞれの Cluster で管理されます。 Tribe Node と言う特別な Node は、検索リクエストをバックエンドの Cluster へ伝播させるプロキシ的な役割を担います。
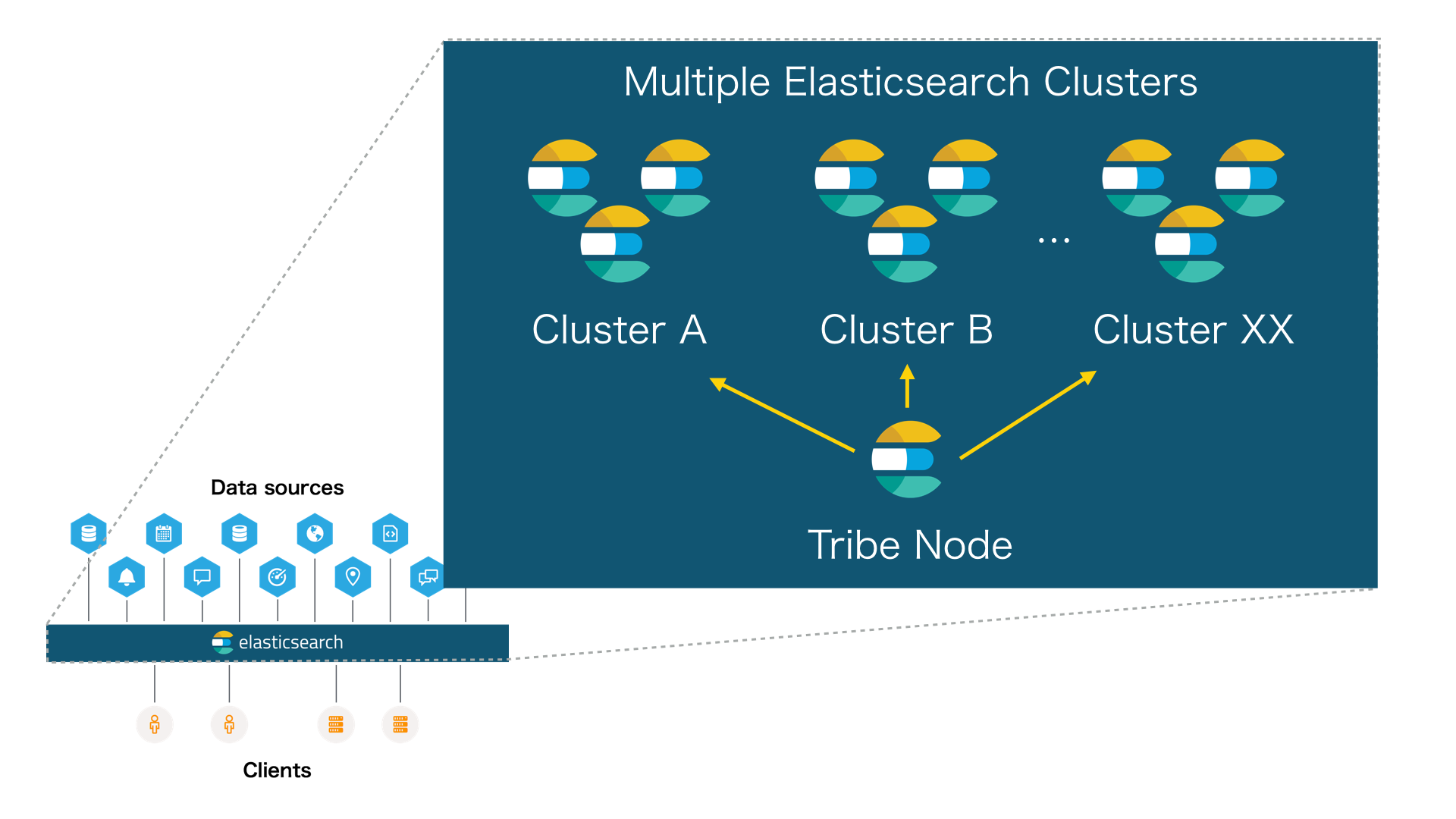
この構成は、パフォーマンス面、運用面、障害発生時のリスクをどう考えるかによって検討するのが良いでしょう。 例えば、e コマースサイトで商品情報などサイト上で公開するデータと、アクセスログなど管理者が分析のみで使用するデータを同じ Cluster で管理する場合を考えてみます。 この場合、大規模なアクセスログのインデックス処理の影響が、一般のユーザが利用する商品情報検索のパフォーマンスにも影響する可能性があります。このような影響が大きい場合は Cluster を分けて運用することを検討します。
また、Tribe Node 必ずしも必要ではありません。複数の Cluster を横断して検索する要件があれば採用すれば良いと思います。
様々な種類のデータを横断して検索・分析できる
Elasticsearch は複数の Index に対して柔軟に横断検索することができます。 以下はそのバリエーション例です。
/_search- すべてのインデックス内のすべてのタイプを対象に検索する
/blog/_search- blog インデックス内のすべてのタイプを対象に検索する
/blog,author/_search- blog と author インデックス内のすべてのタイプを対象に検索する
/b*,a*/_search- b から始まるインデックスと、a から始まるインデックス内のすべてのタイプを対象に検索する
/blog/posts/_search- blog インデックス内の posts タイプを対象に検索する
/blog,author/posts,users/_search- blog と author インデックス内の posts と users タイプを対象に検索する
/_all/posts,users/_search- すべてのインデックス内の posts と users タイプを対象に検索する
Tribe Node を利用する場合も同じです。ただし、すべての Cluster で Index 名が一意に識別できるように作成する必要があります。
高速なクエリ実行とリアルタイム分析
Elasticsearch は元のデータをそのまま保存するのではなく、高速に検索できるようにトークン単位でインデックスを作ります。1冊の本に例えるなら本の末尾にある索引を作るイメージです。
検索や分析の際は、その索引ページからクエリ条件にあったドキュメント探して結果を高速に返します。
システム的には、リクエストを受け付けた Node が Shards が配置されている 他の Nodes に対してリクエストし、 各 Nodes から得られた検索結果をマージして検索結果を返します。データのインデックス時も同じように処理が複数の Nodes で分散される仕組みです。
様々種類のスキーマに対応可能
Elasticsearch にインデックスするドキュメント(データ)は、JSON 形式のデータを受け付けます。 そのため、フラットな構造のデータだけでなく、ネストされたデータもインデックス可能です。
{
"employee_id": 0,
"firstname": "Kay",
"lastname": "Ward",
"email": "todd.nguyen@classmethod.jp",
"salary": 726428,
"age": 38,
"gender": "male",
"phone": "+1 (917) 512-3882",
"address": "720 Maujer Street, Graniteville, Virgin Islands, 6945",
"joined_date": "2014-10-24",
"location": {
"lat": 72.434989,
"lon": 48.395502
},
"married": false,
"interests": ["Auto Scaling", "Amazon Cognito"],
"friends": [{
"firstname": "Melba",
"lastname": "Hobbs"
}]
}
このように JSON で表現出来るデータは Elasticsearch にそのままインデックスして検索・分析可能なため、 考えられる種類のデータのほとんどは対応できるのではないでしょうか。
様々な種類のデータ型に対応可能
Elasticsearch のサポートするデータ型は他のデータベースよりも豊富です。
- Core datatypes
- Complex datatypes
- Geo datatypes
- Specialised datatypes
Core datatypes
基本的なデータタイプの一覧です。基本的な型はほとんど網羅しています。
- String datatype
string
- Numeric datatype
long,integer,short,byte,double,float
- Date datatype
date
- Boolean datatype
boolean
- Binary datatype
binary
Complex datatypes
JSON をサポートするための特殊なデータタイプの一覧です。
- Array datatype
- Array support does not require a dedicated
type
- Array support does not require a dedicated
- Object datatype
objectfor single JSON objects
- Nested datatype
nestedfor arrays of JSON Objects
Geo datatypes
ロケーション検索用のデータタイプです。半径何メートル以内の情報を検索するなど、緯度・経度をベースにした検索に利用します。
- Geo-point datatype
geo_pointfor lat/lon points
- Geo-Shape datatype
geo_shapefor complex shapes like polygons
Specialised datatypes
特殊なデータタイプの一覧です。この辺りは、Elasticsearch ならではのデータタイプです。文字列で表現される IPv4 のデータに対して、範囲検索ができたりします。
また、attachments を使用することで、PDF などの内容をインデックス化し、検索できるようになります。
- IPv4 datatype
ipfor IPv4 addresses
- Completion datatype
completionto provide auto-complete suggestions
- Token count datatype
token_countto count the number of tokens in a string
- mapper-murmur3
murmur3to compute hashes of values at index-time and store them in the index
- Attachment datatype
mapper-attachments plugin which supports indexing
attachmentslike Microsoft Office formats, Open Document formats, ePub, HTML, etc. into an attachment datatype.
多分、こんなに多くのデータタイプをサポートしているデータベースは、他にないですよね?
柔軟なデータモデル
Elasticsearch は JSON のフォーマットをベースにスキーマレスなデータモデルをサポートしています。 例えば、フィールドの追加なども JSON にフィールドを追加してインデックスするだけで検索可能になります。
高度なクエリ言語
Elasticsearch はクエリ言語として JSON ベースの Query DSL を提供しています。 構造化された JSON フォーマットで、論理的に組み立てやすくさまざななクエリを提供しています。
- Queries
- データのフィルタリングやスコアリングなど50近い Query をサポートしています。
- Aggregations
- データの集計・分析など50近い Aggregation をサポートしています。
{
"query": {
"bool": {
"must": [{
"match": {
"title": "Search"
}
}, {
"match": {
"content": "Elasticsearch"
}
}],
"filter": [{
"term": {
"status": "published"
}
}, {
"range": {
"publish_date": {
"gte": "2015-01-01"
}
}
}]
}
},
"aggs": {
"group_by_category": {
"terms": {
"field": "category"
},
"aggs": {
"avg_views": {
"avg": {
"field": "views"
}
}
}
}
}
}
このクエリは、検索条件にマッチしたドキュメントの検索結果一覧と、その検索結果を元にカテゴリ別ベージビュの平均を返します。
想像しているよりもはるかに複雑なことができる
例えば、商品情報を対象に以下のような情報を1ページ内で表示したいとしましょう。 商品情報には基本情報の他に大・中・小カテゴリ情報/メーカ情報/価格情報/公開日付/販売数などの情報もあるとします。
1ページ内に表示したい内容
- 画面左ナビゲーション
- 公開済みの商品情報を対象に中カテゴリ別、メーカ別、価格別のナビゲーションを表示
- それぞれのナビゲーションには10項目づつ表示しそれぞの商品数も掲載
- パンくず
- 公開済みかつフリーワードにマッチした商品情報を対象に各階層ごとの大・中・小カテゴリをパンくず表示
- カテゴリ別売れ筋ベスト3
- 公開済みかつフリーワードにマッチした商品情報を対象にカテゴリ別のトップ3商品情報を表示
- 各カテゴリの表示順は検索結果のスコアの高い商品情報を含むカテゴリを優先して表示
- フリーワード検索結果
- 公開済みかつフリーワードにマッチした商品情報をスコアの高い順で一覧表示
- 同一スコアの場合は公開日付が新しいものを優先
この情報を得るために Elasticsearch へは、最小で何回リクエストすればよいでしょうか?
答えは1回です。衝撃的に複雑なことができます。 フロントエンドのアプリケーションは受け取った情報を元にほとんど加工なしに表示できるだけの情報を返すことができます。
これだけ複雑なことができれば、Elasticsearch の適用範囲も広がりそうですね。
まとめ
いかがでしたでしょうか。Elasticsearch は RESTful な API を兼ね備えていますので、様々なデータを Elasticsearch に統合するだけで。API プラットフォームを構築可能です。是非 Elasticsearch の利用範囲を拡大して、データをもっと便利に活用しましょう。








